
library("affy")
Data<-ReadAffy();
eset<-mas5(Data,normalize=T)
if (method=='mas5')
{
if(norm=='F')
{ eset<-mas5(Data,normalize=F) } else { eset<-mas5(Data,normalize=T) }
}
if (method=='rma')
{ eset <-rma(Data) }
chip.names <- rownames( attr(attr(Data,'phenoData'),'data') );
expdata <- exprs(eset);
colnames(expdata) <- chip.names;
write.table(expdata,file="mas5.txt",sep="\t");
2011年12月21日 星期三
2011年12月11日 星期日
Paper Size
紙張尺寸及示意圖
ISO 216定義了A、B、C三個系列的紙張尺寸。C系列紙張尺寸主要使用於信封。
ISO 216的格式遵循著 的比率;放在一起的兩張紙有著相同的長寬比和側邊。這個特性簡化了很多事,例如:把兩張A4紙張縮小影印成一張A4紙張;把一張A4紙張放大影印到一張A3紙張;影印並放大A4紙張的一半到一張A4紙張等等。
| |||||
A系列 | B系列 | C系列 | |||
A0 | 841×1189 | B0 | 1000×1414 | C0 | 917×1297 |
A1 | 594×841 | B1 | 707×1000 | C1 | 648×917 |
A2 | 420×594 | B2 | 500×707 | C2 | 458×648 |
A3 | 297×420 | B3 | 353×500 | C3 | 324×458 |
A4 | 210×297 | B4 | 250×353 | C4 | 229×324 |
A5 | 148×210 | B5 | 176×250 | C5 | 162×229 |
A6 | 105×148 | B6 | 125×176 | C6 | 114×162 |
A7 | 74×105 | B7 | 88×125 | C7 | 81×114 |
A8 | 52×74 | B8 | 62×88 | C8 | 57×81 |
A9 | 37×52 | B9 | 44×62 | DL | 110×220 |
A10 | 26×37 | B10 | 31×44 | C7/6 | 81×162 |

{kind=link}
A系列紙張尺寸的長寬比都是 ,然後捨去到最接近的毫米值。A0定義成面積為一平方公尺,長寬比為 的紙張。接下來的A1、A2、A3......等紙張尺寸,都是定義成將編號前一號的紙張沿著長邊對折,然後捨去到最接近的毫米值。最常用到的紙張尺寸是A4,它的大小是210乘以297毫米。
B系列紙張尺寸是編號相同與編號前一號的A系列紙張的幾何平均。舉例來說,B1是A1和A0的幾何平均。同樣地,C系列紙張尺寸是編號相同的A、B系列紙張的幾何平均。舉例來說,C2是B2和A2的幾何平均。此外,日本有一種不相容的B系列紙張尺寸,是用算術平均而不是用幾何平均來定義的。
C系列紙張尺寸主要使用於信封。一張A4大小的紙張可以剛好放進一個C4大小的信封。如果你把A4紙張對折變成A5紙張,那它就可以剛好放進C5大小的信封,如此類推。
2011年12月7日 星期三
Survival analysis name
Survival analysis
因病存活率(OS = overall cause specific survival)局部無復發存活率(LRRFS = local regional relapse free survival)
遠端無轉移存活率(MFS = distant metastasis free survival)
無病存活率(DFS = disease free survival)
2011年12月1日 星期四
[VBA] 刪除字串中頭尾的空白字元
應用範例1
Sub 刪除字串前端的空白字元()
MsgBox “刪除使用中儲存格內字串前端的空白字元”
ActiveCell.Value = LTrim(ActiveCell.Value)
End Sub
應用範例2
Sub 刪除字串前後端的空白字元()
moji = “ 彭 凱堯 ”
MsgBox “將變數moji前後端加上星號以利辨認其空白字元”
MsgBox “*” & moji & “*”
MsgBox “接著,刪除moji前後端的空白字元後,在其前後端加上星號,比較刪除前後的差異”
MsgBox “*” & Trim(moji) & “*”
End Sub
TRIM 刪除頭及尾空白字元函數:將字串開頭及結尾的空白字元刪除。
LTRIM 刪除開頭空白函數:將字串開頭的空白字元刪除。
RTRIM 刪除結尾空白函數:將字串結尾的空白字元刪除。
Sub 刪除字串尾端的空白字元()
MsgBox “刪除使用中儲存格內字串尾端的空白字元”
ActiveCell.Value = RTRIM(ActiveCell.Value)
End Sub
[SQL] 尋找區間內物件
create table hg18_encode_region_match_cgh
select t1.*, t2.ID, t2.nstart_pos, t2.nend_pos, concat(t2.band1,t2.band2) as band, t2.gene_sym, t2.gene_name from hg18_encode_region as t1, cell_cycle_10meant_INFO as t2
WHERE
t1.chr = t2.chrom
and
t1.start_pos <= t2.nend_pos
and
t2.nstart_pos <= t1.end_pos
[VBA] 找出最大值並上色
Sub 找出最大值並上色()
'獲得矩陣大小
Dim n As Integer
n = Range("A1").End(xlDown).Row
MsgBox (" Total Row = " & n)
'將對角線以*符號替代
Dim x As Variant
Dim y As Variant
For x = 1 To n
Cells(x, x) = "*"
Next
''找尋每列中的最大值上黃色,最小值上紅色
Dim A As Variant
Dim MAX_V As Variant
Dim MIN_V As Variant
For y = 1 To n
A = Range(Cells(y, 1), Cells(y, n))
MAX_V = Application.WorksheetFunction.Max(A)
MIN_V = Application.WorksheetFunction.Min(A)
For x = 1 To n
If Cells(y, x) = MAX_V Then
Cells(y, x).Interior.ColorIndex = 6
Else
If Cells(y, x) = MIN_V Then
Cells(y, x).Interior.ColorIndex = 3
End If
End If
Next
Next
'將對角線*符號換回1
For x = 1 To n
Cells(x, x) = "1"
Next
End Sub
2011年11月28日 星期一
[VBA] normscore functiom
## 套用在模組中
Function normscore(inde_num As Double, ref_leng As range)
X = Application.WorksheetFunction.Rank(inde_num, ref_leng, 1)
Y = Application.WorksheetFunction.Count(ref_leng) + 1
Z = Application.WorksheetFunction.NormSInv(X / Y)
normscore = Z
End Function
2011年11月23日 星期三
Genome Sizes
| Base pairs | Genes | Notes | |
|---|---|---|---|
| φX174 | 5,386 | 11 | virus of E. coli |
| Human mitochondrion | 16,569 | 37 | |
| Epstein-Barr virus (EBV) | 172,282 | 80 | causes mononucleosis |
| Nanoarchaeum equitans | 490,885 | 552 | This parasitic member of the Archaea has the smallest genome of a true organism yet found. |
| nucleomorph of Guillardia theta | 551,264 | 511 | all that remains of the nuclear genome of a red alga (a eukaryote) engulfed long ago by another eukaryote |
| Mycoplasma genitalium | 580,073 | 485 | two of the smallest true organisms |
| Mycoplasma pneumoniae | 816,394 | 680 | |
| Chlamydia trachomatis | 1,042,519 | 936 | this bacterium causes the most common sexually-transmitted disease (STD) in the U.S. |
| Rickettsia prowazekii | 1,111,523 | 834 | bacterium that causes epidemic typhus |
| Treponema pallidum | 1,138,011 | 1,039 | bacterium that causes syphilis |
| Mimivirus | 1,181,404 | 1,262 | A virus (of an amoeba) with a genome larger than the six cellular organisms above |
| Pelagibacter ubique | 1,308,759 | 1,354 | smallest genome yet found in a free-living organism (marine α-proteobacterium) |
| Borrelia burgdorferi | 1.44 x 106 | 1,738 | bacterium that causes Lyme disease [Note] |
| Campylobacter jejuni | 1,641,481 | 1,708 | frequent cause of food poisoning |
| Helicobacter pylori | 1,667,867 | 1,589 | chief cause of stomach ulcers (not stress and diet) |
| Thermoplasma acidophilum | 1,564,905 | 1,509 | These unicellular microbes look like typical bacteria but their genes are so different from those of either bacteria or eukaryotes that they are classified in a third kingdom: Archaea. |
| Methanococcus jannaschii | 1,664,970 | 1,783 | |
| Aeropyrum pernix | 1,669,695 | 1,885 | |
| Methanobacterium thermoautotrophicum | 1,751,377 | 2,008 | |
| Haemophilus influenzae | 1,830,138 | 1,738 | bacterium that causes middle ear infections |
| Streptococcus pneumoniae | 2,160,837 | 2,236 | the pneumococcus |
| Neisseria meningitidis | 2,184,406 | 2,185 | Group A; causes occasional epidemics of meningitis in less developed countries. |
| Neisseria meningitidis | 2,272,351 | 2,221 | Group B; the most frequent cause of meningitis in the U.S. |
| Encephalitozoon cuniculi | 2,507,519 | 1,997 | (plus 69 RNA genes); a parasitic eukaryote. |
| Propionibacterium acnes | 2,560,265 | 2,333 | causes acne |
| Listeria monocytogenes | 2,944,528 | 2,926 | 2,853 of these encode proteins; the rest RNAs |
| Deinococcus radiodurans | 3,284,156 | 3,187 | on 2 chromosomes and 2 plasmids; bacterium noted for its resistance to radiation damage |
| Synechocystis | 3,573,470 | 4,003 | a marine cyanobacterium ("blue-green alga") |
| Vibrio cholerae | 4,033,460 | 3,890 | in 2 chromosomes; causes cholera |
| Mycobacterium tuberculosis | 4,411,532 | 3,959 | causes tuberculosis |
| Mycobacterium leprae | 3,268,203 | 1,604 | causes leprosy |
| Bacillus subtilis | 4,214,814 | 4,779 | another bacterium |
| E. coli K-12 | 4,639,221 | 4,377 | 4,290 of these genes encode proteins; the rest RNAs |
| E. coli O157:H7 | 5.44 x 106 | 5,416 | strain that is pathogenic for humans; has 1,346 genes not found in E. coli K-12 |
| Agrobacterium tumefaciens | 4,674,062 | 5,419 | Useful vector for making transgenic plants; shares many genes with Sinorhizobium meliloti |
| Salmonella enterica var Typhi | 4,809,037 | 4,395 | + 2 plasmids with 372 active genes; causes typhoid fever |
| Salmonella enterica var Typhimurium | 4,857,432 | 4,450 | + 1 plasmid with 102 active genes |
| Yersinia pestis | 4,826,100 | 4,052 | on 1 chromosome + 3 plasmids; causes plague |
| Schizosaccharomyces pombe | 12,462,637 | 4,929 | Fission yeast. A eukaryote with fewer genes than the four bacteria below. |
| Ralstonia solanacearum | 5,810,922 | 5,129 | soil bacterium pathogenic for many plants; 1681 of its genes on a huge plasmid |
| Pseudomonas aeruginosa | 6.3 x 106 | 5,570 | Increasingly common cause of opportunistic infections in humans. |
| Streptomyces coelicolor | 6,667,507 | 7,842 | An actinomycete whose relatives provide us with many antibiotics |
| Sinorhizobium meliloti | 6,691,694 | 6,204 | The rhizobial symbiont of alfalfa. Genome consists of one chromosome and 2 large plasmids. |
| Saccharomyces cerevisiae | 12,495,682 | 5,770 | Budding yeast. A eukaryote. |
| Cyanidioschyzon merolae | 16,520,305 | 5,331 | A unicellular red alga. |
| Plasmodium falciparum | 22,853,764 | 5,268 | Plus 53 RNA genes. Causes the most dangerous form of malaria. |
| Thalassiosira pseudonana | 34.5 x 106 | 11,242 | A diatom. Plus 144 chloroplast and 40 mitochondrial genes encoding proteins |
| Neurospora crassa | 38,639,769 | 10,082 | Plus 498 RNA genes. |
| Naegleria gruberi | 41 x 106 | 15,727 | This free-living unicellular organism lives as both an amoeboid and a flagellated form. 4,133 of its genes are also found in other eukaryotes suggesting that they were present in the common ancestor of all eukaryotes. The great variety of functions encoded by these genes also suggests that the common ancestor of all eukaryotes was itself as complex as many of the present-day unicellular members. |
| Caenorhabditis elegans | 100,258,171 | 21,733 | The first metazoan to be sequenced. |
| Arabidopsis thaliana | 115,409,949 | ~28,000 | a flowering plant (angiosperm) See note. |
| Drosophila melanogaster | 122,653,977 | ~17,000 | the "fruit fly" |
| Anopheles gambiae | 278,244,063 | 13,683 | Mosquito vector of malaria. |
| Tetraodon nigroviridis (a pufferfish) | 3.42 x 108 | 27,918 | Although Tetraodon seems to have more protein-encoding genes than we do, it has much less "junk" DNA so its total genome is about a tenth the size of ours. |
| Rice | 3.9 x 108 | 28,236 | |
| Sea urchin | 8.14 x 108 | ~23,300 | |
| Zebrafish | 1.2 x 109 | 15,761 | |
| Dogs | 2.4 x 109 | 19,300 | |
| Humans | 3.3 x 109 | ~21,000 | [Link to more details.] |
| Mouse | 3.4 x 109 | ~23,000 | |
| Amphibians | 109–1011 | ? | |
| Psilotum nudum | 2.5 x 1011 | ? | Note |
2011年10月5日 星期三
[Coffee] 名詞備忘

小小杯的Espresso,是短時間內快速萃取的濃縮咖啡,可以用他來調配成各式花式咖啡。一般只有30毫升左右,味道很苦。
2) Americano 美式咖啡
小杯Espresso加入大半杯白開水。美式咖啡味道淡顏色淺,微酸微苦,可以加點糖和牛奶調和。
3) Caffé Latte 拿鐵咖啡
拿鐵咖啡是少量Espresso加入大量牛奶,上端會有一層奶泡,奶泡上可以發揮創意拉出各種各樣的拉花圖案。而“歐蕾咖啡”則是會將牛奶和咖啡同時倒入杯中。
4) Cappuccino 卡布奇諾
卡布奇諾和拿鐵咖啡有點相似,都是Espresso+牛奶+奶泡,但卡布奇諾奶泡比牛奶多,拿鐵則是牛奶比奶泡多,因此卡布奇諾通常比拿鐵小杯,且奶泡佔了很大部份,咖啡味濃。
5) Macchiato 瑪奇朵, Caramel Macchiato 焦糖瑪奇朵, Brown Sugar Macchiato 黑糖瑪奇朵
在Espresso只加入一些奶泡。可以大大享受到細膩綿密的奶泡,卻又不失咖啡原本的濃厚。
6) Caffé Mocha 摩卡咖啡
成份有Espresso、牛奶和巧克力醬,上方則是擠上鮮奶油和巧克力醬,另外也可以撒上可可粉或肉桂粉。風味很特別,層次很豐富。
2011年9月28日 星期三
[Drama] Wilfred slogan
EP1:Pilot:Happiness
理智和快樂不可能並存
"Sanity and happiness are an impossible combination." by Mark Twain.
EP2:Trust
只相信自己 就不會被背叛
"Trust thyself only, and another shall not betray thee." by Thomas Fuller.
EP3:Fear
恐懼有它的用處 懦弱卻沒有
"Fear has its use, but cowardice has none." by Mahatma Gandhi.
EP4:Acceptance
寬容才會有幸福 -
"Happiness can exist only in acceptance." by George Orwell.
EP5:Respect
想獲得尊重 就要先尊重自己
"Seek respect mainly from thyself, for it comes first from within." by Steven H. Coogler.
EP6:Conscience
良知是條不咬人的狗 但它總是叫個不停
"Conscience is the dog that can't bite, but will never stop barking." Proverb
EP7:Pride
通常傲慢是所有錯誤的根源
"In general, pride is at the bottom of all great mistakes." by Steven H. Coogler.
EP8:Anger
忍氣吞聲並不能讓怒氣平息 只會讓它越發膨脹
"Anger as soon as fed is dead - tis starving makes it fat." by Emiy Dickinson
EP9:Compassion
沒有憐憫之心 就不要對其妄加評論
"Make no judgements where you have no compassion." by Anne McCaffrey
EP10:Isolation
離群索居是事與願違的夢
"Isolation is a self-defeating dream." by Carlos Salinas de Gortari
EP11:Doubt
防人之心不可無 防過了頭反成仇
"Doubt must be no more than vigilance, otherwise it can become dangerous." by George C. Lichtenberg
EP12:Sacrifice
愛就是心甘情願的犧牲
"Love is a willingness to sacrifice." by Michael Novak
EP13:Identity
身份的價值在於它具有目的性
"The value of identity is that so often with it comes purpose." by Richard R. Grant
2011年9月24日 星期六
[Stat]共線性(Collinearity)與交互(Interaction)作用
| 交互作用 Interaction | 共線性 Collinearty |
範例 | x1、x2 與y y=α+β1x1+β2x2+ε | x1、x2 與y y=α+β1x1+β2x2+ε |
意義 | 2個變項一同對y作用時,有協同或拮抗現象,若2變項對y存在交互作用時,應該只放入交互作用項,EX: x1、x2存在交互作用,則放入迴歸的應為x1*x2,而非x1、x2。 | 2變項之間的相關性很高,通常為Pearson's correlation大於0.8時,EX: x1、x2有高度相關,表示x1、x2對y的影響存在共線性,此時只能選x1、x2其中一個放入迴歸裡,判定的依據為看哪個變項對y的預測比較重要。 |
檢查方法 | TWO-WAY ANOVA | 相關矩陣、CI值、VIF、Tolerance |
結論 | 所以當迴歸分析要放入變項時,要先檢查變項間的共線性,先解決共線性的問題,再去探討是否有交互作用項的存在。 | |
2011年7月21日 星期四
Description of each patient cohort
1) SOTIRIOU et al (http://www.pnas.org/cgi/content/full/1732912100/DC1) - This cohort contained 99 node-negative and node-positive breast cancer patients. All of the tumor samples were invasive ductal carcinomas. 46 individuals were node negative and 53 were node positive. 16 patients with tumor grade 1, 38 patients with tumor grade 2 and 45 patients with tumor grade 3. 65 patients were ER positive and 34 ER negative patients. Two patients received PMF Chemotherapy; 30 patients received CMF; and two received Adrymycin, CMF chemotherapy.
2) BILD et al (GSE3143) - This cohort contained 157 patients, 110 with ER level 1 and 47 with ER level 0.
3) WANG et al (GSE2034) - This cohort contained 286 lymph-node-negative patients of which, 146 were of stage T1, 132 of stage T2, and 8 of stage T3/4. This cohort contained 209 ER positive and 77 ER negative patients. There were 165 PR positive, 111 PR negative and 10 with unknown PR status. 148 patients were with poor grade, 42 with moderate grade, 7 with good grade and 89 with unknown grade. There were 139 pre-menopausal and 147 post-menopausal patients.
4) VAN DE VIJVER et al (http://www.rii.com/publications/2002/nejm.html) - There were 295 consecutive patients with primary breast carcinomas, 151 with lymph node negative disease, and 144 with lymph node positive disease.
5) MILLER et al (GSE3494) – This cohort contained 236 patients, 62 patients with Grade I, 121 with Grade II, 51 with Grade III and 2 patients with unknown grade information. 201patients were ER positive and 31 patients were ER negative. There were 179 PR positive patients and 57 PR negative patients. The cohort contained 78 lymph node positive patients and 149 lymph node negative patients.
6) LOI et al (GSE6532) – This cohort contained 137 untreated patients and 277 tamoxifen treated patients. Gene expression profiles of 327 patients were screened on GPL96 Affymetrix Gene Chip Human Genome U133 Array Set HG-U133A platform and 87 patient expression profiles were generated on GPL570 Affymetrix GeneChip Human Genome U133 plus 2.0 Array. The cohort contained 250 lymph node negative patients and 143 lymph node positive patients. There were 82 patients with Grade I, 182 patients with Grade II, and 76 patients with Grade III. There were 349 ER positive patients and 45 ER negative patients.
7) IVSHINA et al (GSE4922) - This cohort contained patient and tumor samples of the Uppsala and Singapore sets. The Uppsala set was composed of 249 patients. The Singapore set contained 40 patients. There were 211 ER positive patients and 34 ER negative patients. This cohort contained 81 lymph node positive patients and 159 lymph node negative patients.
8) SORLIE et al (GSE4335) - This cohort contained 122 tissue samples of which, 77 carcinomas and 7 nonmalignant tissues were previously published. There were 83 ER positive patients and 32 ER negative patients. There were 34 Lymph node negative patients and 46 lymph node positive patients. The cohort contains 11 patients with Grade I, 49 patients with Grade II, and 53 patients with Grade III.
2011年6月14日 星期二
[R]擷取工作畫面文字
以library("survival"), survfit 為例:
Data.surv<-survfit(Surv(months, death)~ strata(Datacut))
> Data.surv
Call: survfit(formula = Surv(months, death) ~ strata(Datacut))
records n.max n.start events median 0.95LCL 0.95UCL
strata(Datacut)=Datacut=0 82 82 82 27 5.67 3.53 NA
strata(Datacut)=Datacut=1 76 76 76 36 2.68 1.70 NA
今要取出median value 故以
x<-read.table(textConnection(capture.output(Data.surv)),skip=2,header=TRUE)
x$median
即可以得到 [1] 5.67 2.68
2011年5月25日 星期三
[SQL] Query
SELECT *
FROM `u133_best_match_u95_INFO`
WHERE GENE_SYM
IN (
FROM `u133_best_match_u95_INFO`
WHERE GENE_SYM
IN (
"ARF3", "CCND2", "CHD4", "TXNRD1", "PRKAG1", "CCT2", "CREBL2", "VWF", "ITPR2", "TRAFD1", "TIMELESS", "GPRC5A", "NELL2", "PPFIBP1", "KRAS", "TEAD4", "CLSTN3", "LMO3", "WIF1", "PRH1 ", "TSPAN9", "PTPN11", "PTPRR", "SLC4A8", "KLRA1", "AKAP3","PKP2", "FGF6", "GABARAPL1", "CDKN1B", "IGF1", "OLR1", "GRIN2B", "RAD52", "ANAPC5", "WNK1", "STK38L", "FBXL14", "ACVR1B", "KIAA1467", "EMP1", "MRPS35", "PHLDA1", "FLJ22662", "LEMD3", "IFT81", "NINJ2", "CLEC1A", "TMEM16B", "FAM60A", "CASC1","GALNT8", "MANSC1", "PLEKHA5", "BCL2L14", "TM7SF3", "ARNTL2", "TMTC1", "SCYL2", "BCAT1", "IPO8", "ETV6", "KLHDC5", "FAM80B", "DNM1L", "C12orf35", "TSPAN11", "LOH12CR1", "CACNA2D4", "BICD1", "ATN1", "SVOP", "B4GALNT3", "GPR92", "SRGAP1","AEBP2", "RASSF8", "MGC24039", "SOX5", "CACNA1C", "LRMP", "CMAS", "FGD4", "C12orf51"
)2011年4月13日 星期三
[R] Array CGH Parse
[R] GLAD package: Gain and Loss Analysis of DNA
source("http://bioconductor.org/biocLite.R") biocLite("GLAD")Analysis Tool: aCGHtool (http://www.mhh.de/acghtool.html)
library(aCGHtool)
2011年3月15日 星期二
[Perl] 特殊變數
| $_ | The default input and pattern-searching space. |
| $digit | Contains the subpattern from a successful parentheses pattern match. |
| $. | The current input line number of last filehandle read. |
| $! | Contains the current value of errno. |
| $0 | The name of the file of the Perl script. |
| @ARGV | The command line arguments issued when the script was started. |
| @_ | The parameter array for subroutines. |
| %ENV | This associative array contains your current environment. |
$_ 就是「這一個變數」,也是所有迴圈會用到的預設變數。
例如要讓perl 印出1到100:
for(1..100){
print $_;
}
$1..$9 這九個特殊變數就是比對的第n個結果
$! 會顯示錯誤的訊息
ex: open(FILE, "test.txt") or die $!;
結果:
沒有此一檔案或目錄 at ./oparse.pl line 32.
若寫成 open(FILE, "test.txt") or die "$!\n";
結果:
沒有此一檔案或目錄
[Perl] mkdir chdir
my $data = <>;
chomp $data;
@dirname = split(/\.fasta/,$data);
mkdir:建立新的目錄 ex: mkdir($dirname[0],0755) || die "$!\n";
chdir:切換目前工作的目錄 ex: chdir($dirname[0]) || die "$!\n";rename:幫檔案改名
unlink:就像使用rm一樣,unlink可以刪除系統中的某些檔案
2011年3月10日 星期四
[R] install package
以seqLogo為例
2. 就 tar檔丟到指定目錄
3. 於該目錄下 key in : R CMD INSTALL seqLogo_1.6.0.tar.gz
4. 即可安裝
2011年3月7日 星期一
[R]畫Sequence logos for DNA
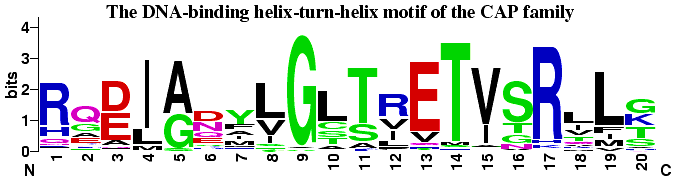
1, web software: WebLogo: http://weblogo.berkeley.edu/
2, R package: "seqLogo": http://bioconductor.org/packages/2.2/bioc/html/seqLogo.html
ex:
source("http://bioconductor.org/biocLite.R")
biocLite("seqLogo")
library("seqLogo")
mFile <- system.file("Exfiles/pwm1", package="seqLogo")
m <- read.table(mFile)
pwm <- makePWM(m)
seqLogo(pwm)

訂閱:
意見 (Atom)